
Recent News in the CCL
Predicting Resources of Tasks in Dynamic Workflows with Bucketing Algorithms at IPDPS 2024
Thanh Son Phung will present Adaptive Task-Oriented Resource Allocation for Large Dynamic Workflows on Opportunistic Resources at the International Parallel and Distributed Processing Symposium 2024.
Non-technical users running dynamic workflows usually have no knowledge of resource (e.g., cores, memory, disk, GPUs) consumption of tasks within a given workflow. However, this omission of information can bring substantial performance degradation as it is important for workflow execution engines to know the exact amount of resources each task takes and make scheduling decisions accordingly.

In the figure above, an application submits many invocations of two functions: f and g. The invocations are transformed into tasks through many layers and scheduled on worker nodes. Note that the resource specification of each task may be unknown.
Since a manual resource specification for each task is unreliable, an automated solution is required. Such solution needs to be (1) general-purpose (can work with any workflow), (2) prior-free (no prior information is used as workflows may change over each run), (3) online (collect information and run as the workflow runs), and (4) robust (performant on many distributions and unexpected changes). The below figure shows two workflows: ColmenaXTB (top row) and TopEFT (bottom row). Resource types range from core, memory, disk, and execution time from left to right.

To predict resources of each task, we first collect resource records of completed tasks, group them into buckets of tasks based on their similarity in resource consumption, and probabilistically choose a bucket to allocate the next task, as shown in the example below.

We introduce two bucketing algorithms, namely Greedy Bucketing and Exhaustive Bucketing, which share the same principle of resource prediction and only differ in the way buckets of tasks are computed.

We compare the two algorithms with five alternative algorithms on 7 workflows with 3 resource types. Results show that Greedy Bucketing and Exhaustive Bucketing consistently outperform other algorithms by yielding the highest resource efficiency in the majority of cases.
Further details can be found in the paper:
- Thanh Son Phung, Douglas Thain, Adaptive Task-Oriented Resource Allocation for Large Dynamic Workflows on Opportunistic Resources, IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 12, May, 2024.
TaskVine at the HEP Analysis Grand Challenge








CCTools 7.8.0 released
We are pleased to announce the release of version 7.8.0 of the
Cooperative Computing Tools from the University of Notre Dame, including
TaskVine, Work Queue, Makeflow, Parrot, Chirp, and other software.
Docs: https://cctools.readthedocs.io/
Download: http://ccl.cse.nd.edu/software/download
Forum: http://ccl.cse.nd.edu/community/forum
This is a feature release that primarily improves the scalability and performance of TaskVine:
Main Features:
TaskVine dask serverless execution (i.e., function calls instead of tasks) to reduce overheads, by @BarrySlyDelgado
TaskVine improvements to library and remove function calls dispatch, by @tphung3
TaskVine temporary file replication, by @colinthomas-z80
TaskVine automatic deletion of ancillary files (unlink_when_done) during workflow execution, by @btovar
TaskVine use of memory buffers to serialize functions, by @btovar
TaskVine cleanup of factory, worker information and stats, by @dthain
Fix TaskVine memory leak in python bindings, by @JinZhou5042
Improved Parsl integration with TaskVine and documentation, by @colinthomas-z80
Full Changelog
Distant Futures at SC 2023
Grad student Barry Sly-Delgado presented his recent work on "Minimizing Data Movement Using Distant Futures" at the research poster session at Supercomputing 2023:


Futures are a widely used concept for organizing concurrent computations. A Future is a variable that represents the result of a function call whose computation may still be pending. When evaluated, the future blocks (if needed) until the result becomes available. This allows for the easy construction of highly parallel programs.
Barry developed a future based execution model for the TaskVine workflow execution system. This allows one to submit and chain function calls written in plain Python. TaskVine then schedules the tasks throughout the cluster, providing a variety of data management services.

However, at very large scales, a natural bottleneck is the return of computed values back to the original manager. To overcome this, we introduce the notion of Distant Futures in which a value is not only pending in time, but potentially left in the cluster on a remote node. Tasks requiring this value can then be scheduled to the same node, or to transfer the value within the cluster, rather than bringing it back home.
Combining distant futures with asynchronous transfer provides significant benefits for applications that are bottlenecked in data transfer, as our results show:

- Barry Sly-Delgado and Douglas Thain, Poster: Minimizing Data Movement Using Distant Futures ACM/IEEE Supercomputing, November, 2023.
Maximizing Data Utility at HPPSS/SC 2023
Thanh Son Phung presented Maximizing Data Utility for HPC Python Workflow Execution at the High Performance Python for Science at Scale workshop at Supercomputing 2023.
This paper describes how the Parsl workflow system integrates with the TaskVine workflow executor in order to run complex Python environments at scale. Parsl provides a function-oriented programming model, generates a large number of tasks to be executed in a graph, and then passes the tasks down to TaskVine for execution on a cluster:

A significant challenging in scaling up Python applications is managing the large body of dependencies in the form of Python modules, system libraries, and so forth, that must be loaded every time a process starts. At very large scales, the cost of pulling all of these resources from a shared parallel filesystem can become a significant bottleneck. (Typically, parallel filesystems are optimized for the delivery of a few large files, rather than a large number of small files.)
TaskVine addresses the problem by exploiting the storage capability of each execution node, which is typically equipped with a local SSD for temporary storage. The TaskVine workers pull data into local storage, and then share files with each other (at the direction of the manager), resulting in less pressure on the shared filesystem, and overall speedups that improve with scale.
This technique was evaluated on a machine learning application requiring a (quite common) 4.4GB of software scaling up from 32 nodes x 16 cores to 256 nodes x 16 cores on a campus HPC cluster. At small scales, TaskVine provides a modest improvement, but as scale increases, the separation becomes more distinct:


For the full details, see our paper here:
|
TaskVine Paper at WORKS/SC 2023
Barry Sly-Delgado presented our overview paper on TaskVine at the Workshop on Workflows in Support of Large Scale Science at Supercomputing 2023 in Denver, Colorado.
TaskVine is a system for executing data intensive workflows on large clusters. These workflows ma consist of thousands to millions of individual tasks that are connected together in a graph structure like this:




For all the details, please check out our paper here:
- Barry Sly-Delgado, Thanh Son Phung, Colin Thomas, David Simonetti, Andrew Hennessee, Ben Tovar, Douglas Thain, TaskVine: Managing In-Cluster Storage for High-Throughput Data Intensive Workflows, 18th Workshop on Workflows in Support of Large-Scale Science, November, 2023. DOI: 10.1145/3624062.3624277
CCTools 7.7.0 Released
We are pleased to announce the release of version 7.7. of the Cooperative Computing Tools from the University of Notre Dame, including TaskVine, Work Queue, Makeflow, Parrot, Chirp, and other software.
- Docs: https://cctools.readthedocs.io/
- Download: http://ccl.cse.nd.edu/software/download
- Forum: http://ccl.cse.nd.edu/community/forum
This is a feature release that primarily improves the scalability and performance of TaskVine:
Main Features:
- TaskVine workers now perform transfers asynchronously while communicating with manager, by @BarrySlyDelgado
- TaskVine Serverless function execution simplified and accelerated by @tphung3
- Improved integration of Parsl and TaskVine by @tphung3
- Improved scheduler performance in Work Queue and TaskVine by @colinthomas-z80
- Multiple improvements to reliability at scale with physics applications by @btovar
- Change to API for cancelling tasks: all tasks are now returned by
vine_waitby @dthain - Change to serverless resource management: functions consume library resources by @dthain
- Improved visualization by @JinZhou5042
- New environment.yml for development dependencies by @thieber22
Full Changelog: nightly...release/7.7.0
Tue, 03 Oct 2023 17:15:00 +0000CCTools 7.6.1 Released
We are pleased to announce the release of version 7.6.1
of the Cooperative Computing Tools from the University of Notre Dame,
including TaskVine, Work Queue, Makeflow, Parrot, Chirp, and other software.
Forum: http://ccl.cse.nd.edu/community/forum
This release introduces several bug fixes and minor improvements to the TaskVine workflow executor and Work Queue scheduler.
TaskVine:
- Fix bug in execution of Dask task graphs that would lead to a hang. (Ben Tovar)
- Fix bug in deployment of serverless LibraryTask. (Thanh Phung)
- Add option to specify Python package dependencies inline. (Barry Sly-Delgado)
- Add visualization of task graph and documentation. (Douglas Thain)
Work Queue:
CCTools 7.6.0 Released
We are pleased to announce the release of version 7.6.0
of the Cooperative Computing Tools from the University of Notre Dame,
including TaskVine, Work Queue, Makeflow, Parrot, Chirp, and other software.
- Docs: https://cctools.readthedocs.io
- Download: http://ccl.cse.nd.edu/software/download
- Forum: http://ccl.cse.nd.edu/community/forum
This release introduces a number of performance, usability, and
documentation improvements to the TaskVine workflow executor.
TaskVine -
- Integration with Parsl workflow system. (Thanh Phung)
- Integration with Dask workflow system (Ben Tovar)
- Optimized scheduling performance with large numbers of workers. (Colin Thomas)
- Enhanced dispatch performance for small tasks. (Colin Thomas)
- vine_submit_workers combined tool for submtting workers. (Thanh Phung)
- Improved generation of file cache names (Barry Sly-Delgado)
- fetch_file interface to obtain cached files in the cluster. (Douglas Thain)
- Worker-to-worker authentication for peer transfers.
- Updated documentation. (All)
Work Queue:
- Enhanced dispatch performance for small tasks. (Colin Thomas)
Makeflow:
- Now supports TaskVine as an execution mode. (Douglas Thain)
General:
- TCP catalog updates are performed in a background process to reduce latency.
Thanks goes to the contributors for many features, bug fixes, and tests:
Thanh Son Phung
Barry Sly-Delgado
Colin Thomas
Ben Tovar
Douglas Thain
Enjoy!
Intro to TaskVine at GCASR 2023
Prof. Thain gave the afternoon keynote (Data Intensive Computing with TaskVine) at the GCASR Workshop in Chicago on April 24th. TaskVine is our latest workflow execution system, just released in March 2023.
The key idea of TaskVine is to exploit the local storage already embedded into clusters for use by complex workflows:

To accomplish this, each node runs a general purpose worker process that manages cached data under unique names, and runs each task within a private namespace:



CCTools version 7.5.2 released
The software may be downloaded here:
http://ccl.cse.nd.edu/software/download
This is our first release of TaskVine, our new data intensive workflow execution system. TaskVine make extensive use of in-cluster storage to accelerate workflows, so that data "grows like a vine" through the cluster. See our extensive documentation and examples to learn more!
- [TaskVine] First official release (Everyone!)
- [General] Change catalog update to tcp by default (D. Thain)
- [Work Queue] Specify manager as an argument when using the factory in python (Ben Tovar)
- [Work Queue] New dynamic resource allocation strategies (Thanh Phung)
Thanks goes to the contributors for many features, bug fixes, and tests:
- Matthew Carbonaro
- Jachob Dolak
- Joseph Duggan
- Kelci Mohrman
- Thanh Son Phung
- David Simonetti
- Barry Sly-Delgado
- Douglas Thain
- Colin Thomas
- Ben Tovar
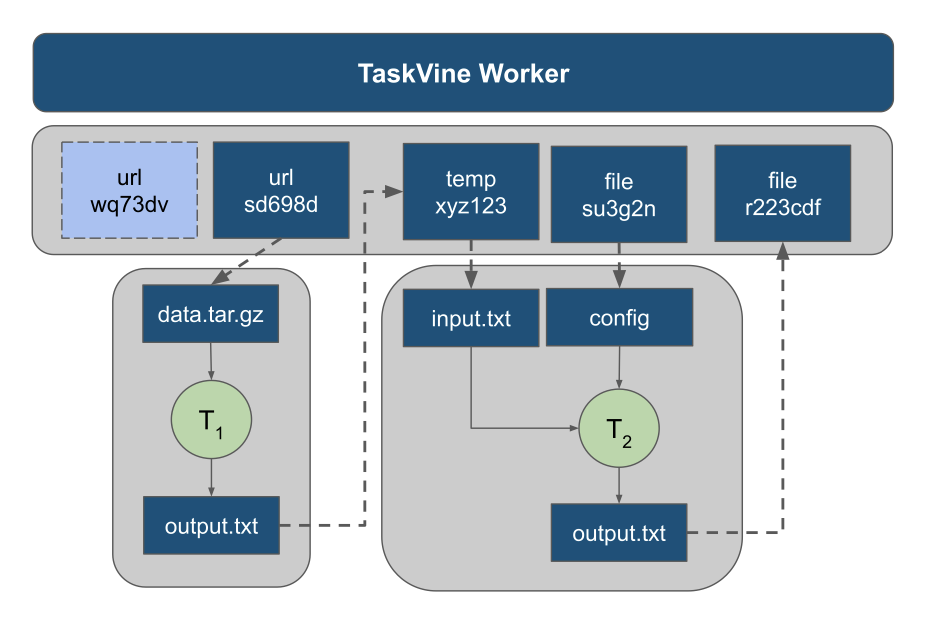
TaskVine System Architecture
TaskVine is our newest framework for building large scale data intensive dynamic workflows. This is the second in a series of posts giving a brief introduction to the system.
A TaskVine application consists of a manager and multiple workers running in a cluster. The manager is a Python program (or C if you prefer) that defines the files and tasks making up a workflow, and gives them to the TaskVine library to run. Both the files and the tasks are distributed to the workers and put together in order to produce the results. As a general rule, data is left in place on the workers wherever possible, so that it can be consumed by later tasks, rather than bringing it back to the manager.
The workflow begins by declaring the input files needed by the workflow. Here, "file" is used generally and means any kind of data asset: a single file on the filesystem, a large directory tree, a tarball downloaded from an external url, or even just a single string passed from the manager. These files are pulled into the worker nodes on the cluster as needed. Then, the manager defines tasks that consume those files. Each task consumes one or more files, and produces one or more files.
A file declaration looks like one of these:
a = FileURL("http://server.edu/path/to/data.tar.gz")
b = FileLocal("/path/to/simulate.exe")
c = FileTemp()
And then a task declaration looks like this:
t = Task("simulate.exe -i input.dat")
t.add_input(a,"simulate.exe")
t.add_input(b,"input.dat")
t.add_output(c,"output.txt")
Tasks produce files which get consumed by more tasks until you have a large graph of the entire computation that might look like this:

To keep things clean, each task runs in a sandbox, where files are mapped in as names convenient to that task. As tasks produce outputs, they generally stay on the worker where they were created, until needed elsewhere. Later tasks that consume those outputs simply pull them from other workers as needed. (Or, in the ideal case, run on the same node where the data already is.).
A workflow might run step by step like this:


You can see that popular files will be naturally replicated through the cluster, which is why we say the workflow "grows like a vine" as it runs. When final outputs from the workflow are needed, the manager pulls them back to the head node or sends them to another storage target, as directed.
A Preview of TaskVine
We have seemed a bit quiet in the Cooperative Computing Lab lately, as we have been focused on building TaskVine, our new system for executing dynamic data intensive workflows.
I am excited that TaskVine is up and running in the lab now! We are working on refining a few technical issues and completing documentation and examples before making a general release. I would like to share some of the details and philosophy of the system as a preview before general availability.
TaskVine builds upon our many years of experience building large scale workflow systems that manage millions of jobs running on thousands of nodes in clusters, clouds, and grids. Some of our prior systems include Makeflow, which enabled the construction of large (static) task graphs to run on batch systems; Work Queue, which enabled the creation of applications that define and consume tasks dynamically; and Prune, which enabled the management of reproducible and shareable computations. (And you can still use those systems if you like.)
TaskVine has some familiar concepts: it too allows the creation of large dynamically parallel distributed applications. But where it really shines is in data management.
In TaskVine, data is first class citizen alongside tasks. Large data sets, software packages, and software services are explicitly declared and put into a working cluster where they can be replicated and shared among nodes. As an application runs, source data and derived results stay in the cluster and gradually creep from node to node, accelerating future tasks. Even later workflows can take advantage of data prepared or produced by prior workflows. We say that the workflow "grows like a vine" through the cluster.

The upshot is that TaskVine takes load off of the facility shared filesystem, which is often the bottleneck in scaling up large applications. Big software stacks, reference datasets, and intermediate steps are made accessible on the worker nodes in a disciplined way, rather than a thousand nodes pounding the same filesystem at once.
Of course, to make all this happen, there are a lot of fine details. In the next few posts, I'll give you an overview of the system architecture, and the new capabilities that we are building out.
Landlord Container Paper in TPDS 2023
Our latest work on container management was recently accepted to IEEE TPDS:
LANDLORD: Coordinating Dynamic Software Environments to Reduce Container Sprawl
his paper is the result of a continuing collaboration between the CCL at Notre Dame and the Parsl group at University of Chicago, led by Dr. Kyle Chard. Recent PhD grad Tim Shaffer led this work as part of a DOE Computational Science Graduate Fellowship, and current PhD student Thanh Phung joined the project and helped us to view the problem from a clustering perspective.




As in most computer systems, there isn't one single number that is the answer: rather, it is a tradeoff between desiderata. Here, we have a broad sweet spot around alpha=0.8. But the good news is that the system has a broad "operational zone" in which the tradeoff is productive.
- Tim Shaffer, Thanh Son Phung, Kyle Chard, and Douglas Thain, LANDLORD: Coordinating Dynamic Software Environments to Reduce Container Sprawl, IEEE Transactions on Parallel and Distributed Systems, to appear in 2023. DOI: 10.1109/TPDS.2023.3241598
Mufasa: Robust Meta-Workflow Management at eScience 2022

- Ben Lyons and Douglas Thain, Robust Meta-Workflow Management with Mufasa, IEEE International Conference on eScience, October, 2022. [Short Paper] [Poster Image]
pyHEP 2022: Automatic resource management with Coffea and WorkQueue
pyHEP is a virtual workshop to discuss the use of python in the High Energy Physics community. In this year pyHEP (2022), we showcased the resource management features that Work Queue offers when executing HEP analysis workflows using the Coffea framework. We showed how Work Queue is able to automatically tailor the resources allocated (cores, memory, disk) to the tasks executed, and how it modify the size of the tasks so that they can fit the resources available.
You can access the jupyter notebook we used for the talk here: https://github.com/cooperative-computing-lab/coffea-wq-notebook
![]()

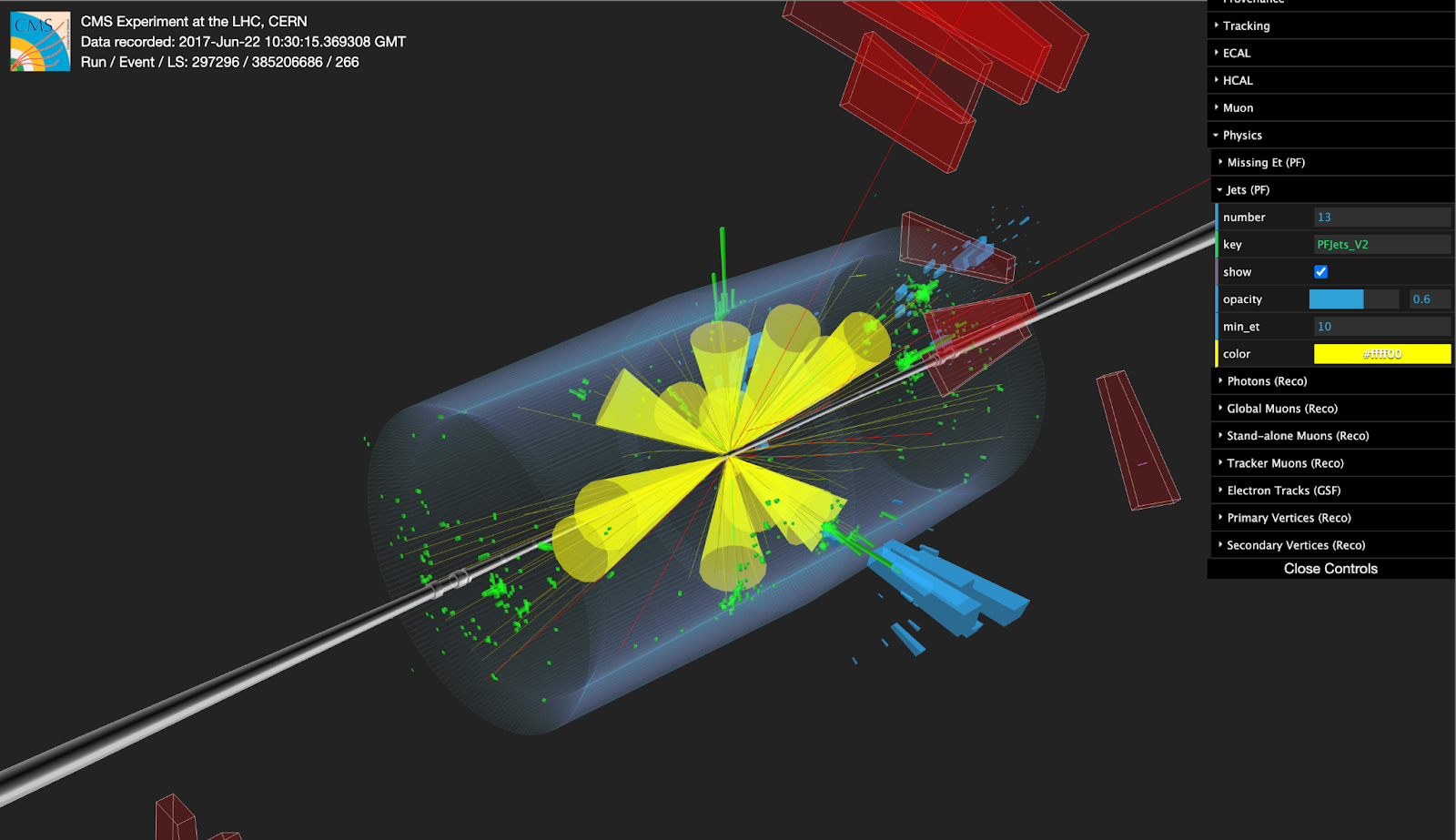
US-CMS PURSUE internship project: Searching for Extreme Events in Multi-lepton Data from the LHC
As part of the US-CMS PURSUE summer internship project, we hosted Xinyue Wu, a rising junior from the University of Rochester. The purpose of the internship is to provide a real research experience to undergrad students in topics related to the CMS particle detector of the Large Hadron Collider. Xinyue implemented a process to search for collision events of interest from real data provided by the CMS detector, and compared the results obtained to predicted yields as computed from simulation data. The events found were then visualized using tools provided by the CMS software environment.
For this project, Xinyue quickly learned how to use different technologies related to CMS analysis workflows running at scale in a distributed system. These included HTCondor, Coffea, TopCoffea, and Work Queue. Xinyue was able to run this analysis workflow using hundreds of cores at the University of Notre Dame compute nodes.
We thank Ph.D. candidate Kelci Mohrman and Prof. Kevin Lannon for their support and input. We congratulate Xinyue on the very successful completion of this project!
Demo of the Work Queue executor at Coffea User's meeting
Last August 15, 2022 we gave a demonstration on how to use Coffea using the Work Queue executor. Coffea is a framework for pulling together all the typical needs of a high-energy collider physics (HEP) experiment analysis using the scientific python ecosystem. Using Coffea on top of Work Queue, we can automatically manage the resources (such as cores, memory, and disk) to maximize the number of concurrent tasks that the application can run. Further, since Work Queue tasks can be created dynamically once the application is running, we can shape the size of tasks (in this case, the number of collision of particle events) so that they better fit the resources available.
For this demo, we also showcased a new status display for Work Queue when used inside a jupyter notebook:

iSURE Project: Visualizing and Right Sizing Work Queue Applications
Samuel Huang, an exchange student in the iSURE program, recently completed a summer project with the Cooperative Computing Lab at the University of Notre Dame. He developed tools for visualizing the performance and behavior of distributed Work Queue applications. These applications can run on thousands of nodes and may have surprisingly complex behavior over time. Visualization is key to understanding what's going on.
For example, this display shows an application consisting of about 30,000 tasks. Each line segment shows one task from beginning to end, sorted by submission time. (The color indicates the type of each task: preprocessing, processing, or accumulation.). As this display clearly shows, this application goes through several distinct phases, in which tasks of different types take increasing amounts of time. In fact, the last few thousands tasks take much longer, showing a classic "long tail" behavior common to distributed applications.


Both these display are now integrated into CCTools in the work_queue_graph_workers tool, which generates a dynamic webpage for digging into the detailed data.
REU Project: TopEFT Performance Analysis: Solving Bottlenecks in Data Transfer and Task Resource Management
Andrew Hennessy, a junior at Notre Dame, recently completed a summer REU project in which he analyzed and improved the performance of TopEFT, a high energy physics analysis application built using the Coffea framework and the Work Queue distributed execution system.
This applications runs effectively in production, but takes about one hour to complete an analysis on O(1000) cores -- we would like to get it down to fifteen minutes or less in order to enable "near real time" analysis capability. Andrew built a visualization of the accumulation portion and observed one problem: the data flow is highly unbalanced, resulting in the same data moving around multiple times. He modified the scheduling of the accumulation step, resulting in a balanced tree with reduced I/O impact.
Next, he observed that processing tasks acting on different datasets have different resource needs: tasks consuming monte carlo (simulated) data take much more time and memory than tasks consuming Production (acquired) data. This results in a slowdown as the system gradually adjusts to the changing task size. The solution here is to ask the user to label the datasets appropriately, and place the Monte Carlo and Production tasks in different "categories" in Work Queue, so that resource prediction will be more accurate.
See the entire poster here:

REU Project: Integrating Serverless and Task Computation in Work Queue
David Simonetti, a junior undergraduate at Notre Dame, recently completed a summer REU project in which he added "serverless" computing capabilities to the Work Queue distributed computing framework.
CCTools version 7.4.9 released
The Cooperative Computing Lab is pleased to announce the release of version 7.4.9 of the Cooperative Computing Tools including Parrot, Chirp, JX, Makeflow, WorkQueue, and other software.
The software may be downloaded here:
http://ccl.cse.nd.edu/software/download
This is a bug fix release:
- [General] Update binary build to OSX-11. (Ben Tovar)
- [General] Several updates to JX documentation. (Douglas Thain)
- [Work Queue] Fix bug where some old files where not deleted from worker's cache. (Ben Tovar)
- [Work Queue] Fix warning message for required size of workers. (Ben Tovar)
- [Work Queue] Add transfers size information to transactions log. (Guanchao Huang)
Thanks goes to the contributors for many features, bug fixes, and tests:
- Andrew Hennessee
- Guanchao Huang
- Kelci Mohrman
- Thanh Son Phung
- David Simonetti
- Barry Sly-Delgado
- Douglas Thain
- Ben Tovar
Please send any feedback to the CCTools discussion mailing list:
http://ccl.cse.nd.edu/community/forum
Enjoy!
How Many Eggs Can You Fit In One Nest?
Prof. Thain gave a talk at HTCondor Week 2022, giving an overview of some of our recent work on resource management in high throughput scientific workflows. An HTCondor talk requires a "bird" metaphor, so I proposed the following question:
How many eggs can you fit in one nest?
A modern cluster is composed of large machines that may have hundreds of cores each, along with memory, disk, and perhaps other co-processors. While it is possible to write a single application to use the entire node, it is more common to pack multiple applications into a single node, so as to maximize the overall throughput of the system.

We design and build frameworks like Work Queue that allow end users to construct high throughput workflows consisting of large numbers of tasks:

But, how does the end user (or the system) figure out what resources are needed by each task? The end user might have some guess at the cores and memory needed by a single task, but these values can change dramatically when the parameters of the application are changed. Here is an example of a computational chemistry application that shows highly variable resource consumption:

CCL grad student Thanh Son Phung came up with a technique that dynamically divides the tasks into "small" and "large" allocation buckets, allowing us to automatically allocate memory and pack tasks without any input or assistance from the user:

Here is a different approach that we use in a high energy physics data analysis application, in which a dataset can be split up into tasks of variable size. Instead of taking the tasks as they are, we can resize them dynamically in order to achieve a specific resource consumption:

Ben Tovar, a research software engineer in the CCL, devised a technique for modelling the expected resource consumption of each task, and then dynamically adjusting the task size in order to hit a resource target:

To learn more, read some of our research research papers:
- Ben Tovar, Ben Lyons, Kelci Mohrman, Barry Sly-Delgado, Kevin Lannon, and Douglas Thain, Dynamic Task Shaping for High Throughput Data Analysis Applications in High Energy Physics, IEEE International Parallel and Distributed Processing Symposium, June, 2022.
- Thanh Son Phung, Logan Ward, Kyle Chard, and Douglas Thain, Not All Tasks Are Created Equal: Adaptive Resource Allocation for Heterogeneous Tasks in Dynamic Workflows, WORKS Workshop on Workflows at Supercomputing, November, 2021.
IPDPS Paper: Dynamic Task Shaping ... in High Energy Physics
In an upcoming paper to be presented at IPDPS 2022, we discuss our experience with designing and executing high throughput data intensive applications for high energy physics. The application itself is pretty cool: TopEFT is a physics application that uses the Coffea framework for parallelization, the Work Queue framework for distributed execution, and XRootD for remote data access:

Configuring such applications to run on large clusters is a substantial end-user problem. It's not enough to write a correct application: one must also select a wide variety of performance parameters, like the data chunk size, the task length, the amount of memory per task, and so on. When these are chosen well, everything runs smoothly. But even one parameter out of tune can result in the application taking orders of magnitude longer than necessary, wasting thousands of resources resources, or simply not running at all. Here is the end-to-end runtime for a few configurations with slight variations:


With these techniques, we are able to relieve the user of the burden of setting a variety of controls, and allow the system to find its own stable configuration. Check it out:
- Ben Tovar, Ben Lyons, Kelci Mohrman, Barry Sly-Delgado, Kevin Lannon, and Douglas Thain, Dynamic Task Shaping for High Throughput Data Analysis Applications in High Energy Physics, IEEE International Parallel and Distributed Processing Symposium, June, 2022.
Scaling Up Julia: Hidden Filesystem Stress
 |
| HTCondor Cluster View |
Here is what we found:
The Julia programming language uses a just-in-time compiler to generate efficient machine code before execution. Julia organizes code in modules, and user applications in projects, where a project is a list of modules. By default, the compilation step is performed every single time an application is executed and considers all the modules listed in the given project. If an end user sets up an application in the normal way, the result is that the code will be compiled simultaneously on all nodes of the system!
# my_modules.jlusing Pkgusing Randomusing Distributionsusing DataFramesusing DataStructuresusing StatsBaseusing LinearAlgebra
# comp.jl
$ strace -f -e trace=%file julia -Jsysimage my_modules.jl |& grep -E '(stat|open)' | wc -l353
So what's the moral of the story?
1 - When moving from a single node to a distributed system, operations that were previously cheap may become more expensive. You can't fix what you can't measure, so use tools like strace to understand the system-call impact of your application.
2 - Avoid exponential behavior, even when individual costs are cheap. Every Julia import results in checking the freshness of that module, and then all of its dependencies recursively, and so leaf modules get visited over and over again. The Julia compiler needs to memoize those visits!