CCTools Hackers Guide
Introduction
This "hacker's guide" is meant to orient new students and external developers
to the layout of the CCTools source code. It is not meant to be a complete listing of all
the quirks of every line of code -- for that you must go to the code.
However, it should provide a roadmap that gives some idea of where to
start, how the pieces fit together, and what new code should look like.
Below, a map of the software shows most of the modules, and contains
hyperlinks to a short blurb about each module and its relationship to
its peers. Use the map to understand the overall layout, and then
proceed to the code. If you add a new module or change the behavior
of an existing module significantly, please update the hacker's guide.
The package is written almost entirely in C. If you aren't an expert
in C, you should get the Kernighan and Ritchie book, and become an expert.
The use of C++ is strongly discouraged for new code.
Although C++ has many interesting features from a software
engineering perspective, it presents enormous challenges for interoperability.
Libaries built with one C++ compiler are generally not usable with code
built by any other C++ compiler. In addition, the sheer complexity of
the language nearly guarantees that valid code will not even compile on
multiple platforms. Note that parts of Parrot were written in
C++, but we are slowly converting this back to C.
Of course, this does not mean that we cannot use object-oriented concepts!
Anything that you could accomplish in C++, you can also accomplish in C,
albeit with slightly different syntax. Instead of declaring a C++ class,
create a C structure and functions that manipulate it. C can even achieve
greater encapsulation than C++ by using factories and hiding structure definitions
from the caller. More on this below.
Basic Structure
The software is divided into several fairly large packages
Note that within each package, a make does what you might expect.
However, to build all packages, you must do a make from the top level.
If you make changes in two distinct packages, you must do a make clean; all
from the top level. The packages are:
chirp - A distributed storage and file system, consisting of a
a server, a set of libraries to access the server, and simple tools that
employ the libraries. Chirp is most easily used by Parrot:
parrot - A tool for attaching new operating-system-like features
to existing applications from user-level. Parrot makes systems like HTTP,
FTP, and Chirp appear as if they were ordinary filesystems visible from
the root directory. Parrot currently only runs on Linux/x86.
dttools - A collection of data structures and other basic
software tools used by the rest of the packages.
ftp_lite - A lightweight FTP library that employs the Globus
toolkit for authentication, but is simple enough to be linked in and used
by other tools.
ftsh - The fault tolerant shell, a novel language for performing
adminsitrative tasks in a distributed, fault prone environment.
maptools - A toolkit for transforming internet addresses into
latitude and longitude. Useful for constructing maps of distributed systems.
Style and Conventions
For an example of general coding style, look at the hash_table module
in the dttools directory. This module would be a good example to follow
when developing new code. Here are some general precepts to follow:
Expose as few details as possible.
Carefully distinguish between public and private members of a module.
Do not simply throw all prototypes and structure definintions
into the header file -- this leads to disaster in large projects.
Instead, identify the smallest set of functions and interfaces that the
outside world needs to know about, and place those in the header file.
Notice, for example, that hash_table.h exposes a few key functions
in the hash_table.h, but makes all structure definitions in hash_table.c.
Protect the namespace. Every module needs to exist in a namespace
so that multiple modules don't accidentally define the name for either functions
or variables. Public items should be prefixed with the module name (hash_table)
while private items may have any reasonable name, provided that they are declared
static or otherwise hidden from view. For example, notice that
struct entry is used within hash_table.c but not visible outside.
In a similar manner, the actualy functions used for hashing strings (jenkins_hash)
are declared static and are invisible to other modules.
Use factories to create private structures. If you need to pass around
a pointer to a structure, but you don't want to reveal its contents, then create
a factory function that returns a pointer to the structure. It is not necessary
to place the structure definition in the header file, because callers may pass
around a pointer without knowing the contents of the structure. For example,
hash_table_create creates a struct hash_table and returns
a pointer to the caller. It is not necessary for the caller to actually see
the definition of struct hash_table, because the pointer will only be
used to pass the structure back to other hash_table functions.
Keep it simple. Keep modules and functions short and sweet.
(There are some exceptions to this, for example, enormous switch statements
such as found in chirp_server and pfs_dispatch are enormous
simply because they have many cases!) The corollary is Divide and conquer:
If you need to implement something complex, attempt to divide it into multiple layers.
For example, the hash_cache module provides a hash table with automatic
data expiration. It is implemented by creating a hash_table and then storing
in it a structure that contains both the data items and the expiration times.
Another example of this is found in Chirp: the chirp_client module implements
the Chirp protocol, but has the possibility of errors. chirp_reli implements
reliability on top of chirp_client. Both of the modules are relatively straightforward,
because they each do one thing well. If we mixed it all into one module, it would be a mess!
CVS for Versioning, C is for Code. The repository records who modified
what code, when they modified it, what was added, what was removed, and so forth.
Anytime we need to go back and look at how and why something was changed, CVS is available.
Conversely, the C code should not be used for this purpose: if we documented who wrote
the code and what the old code was, it would quickly become unreadable. The C code should
be lean and mean and simply reflect how things currently work. Get rid of any uncalled,
unused, or commented-out code.
Use All Your Pixels. How many people on planet Earth use a VT100 to edit and write code?
That's right: none! Don't go out of your way to wrap code to 80 lines, just make your
editor window bigger or rely on visual line wrapping.
By keeping related things on the same line,
it becomes much easier to use simple tools such as grep to analyze the code. For example, if all function arguments are on the same line, it is very easy to grep funcname */* and see all
calls to funcname with the necessary context. Without line wrapping, each instance
must be investigated manually with the editor. Of course, there are reasonable exceptions:
it makes sense to break a 500 character expression into multiple lines of ANDed sub-expressions.
However, in general, don't go around wrapping every 82-column line.
Match Styles. There is no universal "best" coding style. Everyone has their
own favorite tab size and so forth. However, it *is* important to match styles within
the same module, otherwise the code quickly becomes unreadable. If the previous author
used a different tab size, then grit your teeth and use the same size. Use tools such
as indent or change your editor settings to help yourself remember.
Software Map
This map shows the most important modules in the package and their primary relationships.
Note that it does not list every last module; some have very limited use.
Nor does it list all relationships between modules; some, like debug, are used by every other module.
However, it does show the primary flow of control in the most common use cases of the software.
Click on a box for a short blurb about the purpose of the module.
Note on rebuilding this map: To edit and rebuild this map, use xfig
to edit map.fig, and place hyperlinks in the comments of boxes using the
"edit" tool. Then, do a make in the hackers directory.
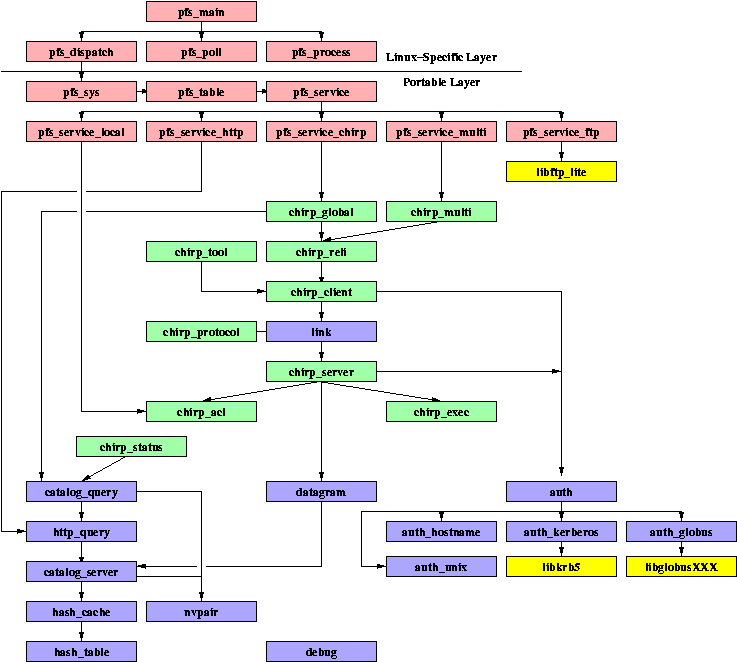
Modules
pfs_main
- Contains the main loop for Parrot that traces children, traps
their system calls, and then invokes pfs_dispatch in order to
handle each system call. Invokes pfs_poll to see when sleeping
processes should wake up and pfs_process in order to create and
destroy child proceses.
(back to map)
pfs_dispatch
- When called by pfs_main, decodes system calls attempted by child
processes. This can be quite complicated and may involve copying
data directly in and out of the child, or forcing the child to
perform certain system calls. Once the call is decoded, it invokes
pfs_sys in the portable layer to implement the system call.
(back to map)
pfs_poll
- Handles the sleep and wakeup facility necessary for dealing with
multiple processes. When a process needs to block on a file descriptor,
it tells pfs poll to watch a particular fd and wake up a given pid
when it is ready. pfs_main calls pfs_poll periodically to check for
wakeups and perform them.
(back to map)
pfs_process
- Stores the basic structures for managing multiple processes.
Tracks the state of each process, and process-specific variables
such as the open file table, current state, parent process, and so forth.
(back to map)
pfs_sys
- The interface between the portable and non-portable parts of Parrot.
pfs_sys is a clean set of functions called to service file accesses.
The calls are not implemented here, but each call is logged on the
debug stream and retried in case of temporary failure. Calls pfs_table
to actually implement the functions.
(back to map)
pfs_table
- IMplements the open file table for one process. Keeps track of all
open files, file location pointers, duplicated files, and so forth.
When a file is opened, pfs_table identifies what service (i.e. filesystem)
should handle the open, and directs the call there.
(back to map)
pfs_service
- An abstract interface that defines what services a filesystem must provide.
Instances of pfs_service represent all sorts of remote filesystems.
The default implementations of pfs_service do nothing but return "not implemented".
(back to map)
pfs_service_local
- Implements access to local filesystems through Parrot.
This is fairly simple. A pfs_open() becomes an open(),
a pfs_pread() becomes a read(), and so forth. Note that when
identity boxing is enabled, pfs_service_local will perform
access control by looking up Chirp-like ACLs, therefore it
also depends on chirp_acl.
(back to map)
pfs_service_http
- Implements access to HTTP servers. Of course, HTTP is not a fully featured
filesystem, so this driver cannot support directory listings, metadata lookups,
and so forth. It only supports sequential reading of files, and emulates stat
operations by simply checking for file existence.
(back to map)
pfs_service_ftp
(back to map)
- Implements access to FTP servers by invoking functions in the ftp_lite library.
Note that FTP does not always correspond closely to Unix operations, so frequently
many operations are needed to determine sufficient detail. For example, this
driver must invoke both a remove SIZE and CDIR in order to determine whether a
remote name is a directory or a file.
pfs_service_chirp
(back to map)
- This very thin driver simply maps operations from PFS UNIX methods into the
corresponding methods in chirp_global. Note that this driver allows the called
to see all known Chirp servers in the top level /chirp directory.
pfs_service_multi
- This very thin driver simply maps operations from PFS UNIX methods into the
corresponding methods in chirp_multi. Note that this driver allows the called
to see all known Chirp servers in the top level /chirp directory.
(back to map)
chirp_global
-Implements a global view of all Chirp servers as if in a single file system.
Uses catalog_query to build a list of all servers, and then uses chirp_reli
to access those servers reliably.
(back to map)
chirp_multi
- Creates a large filesystem spread across multiple Chirp servers.
One server is used to store the directory structure, which contains pointers
to files on other servers. Uses chirp_reli to reliably access each server.
(back to map)
chirp_reli
- Implements a reliability layer on top of chirp_client. A cache of connections
allows the caller to avoid opening and closing connections. When a connection is
lost, chirp_reli is responsible for re-creating the connection and opening
files as needed.
(back to map)
chirp_client
- Implements an RPC interface to the Chirp protocol. Callers must open connections
manually, and then within those connections, make I/O requests to remote servers.
If the connection is lost, the caller must discard the connection object and create another.
Uses the link module to make TCP connections to chirp_servers.
Uses the auth module to authenticate those connections.
(back to map)
chirp_server
- Provides file service to remote users. The main loop forks a new process for each
incoming client, authenticates with the auth module, and then services Chirp requests.
As each request is decoded, permissions are checked using the chirp_acl module, and
then the action is carried out. An experimental facility allows programs to be
executed through the Chirp interface: this is handled by chirp_exec.
(back to map)
chirp_acl
- Implements access control lists on each directory. As chirp_server decodes a Chirp
command, chirp_acl determines whether the action is allowed, according to the ACL
files in each directory. Where there is no ACL, the server treats the caller as
the Unix user nobody.
(back to map)
chirp_tool
- A command-line interface that allows the user to interact with
a single Chirp server at a time, much like an FTP client.
This tool can set and get ACLs, which Parrot is unable to do.
Relies on chirp_client to make connections.
(back to map)
chirp_status
- A command-line tool that queries the catalog server via
http and displays a list of known Chirp servers.
(back to map)
link
- Link is an abstraction over TCP and sockets. It allows the caller to do the expected
things such as make and break connections, read and write data. However, it offers
three distinct benefits. 1 - All operations have clean and explicit timeouts.
2 - Small reads are buffered, to allow for efficient protocol construction.
3 - Connects created and lost are hooked into the debugging system.
(back to map)
datagram
- Datagram is an abstraction over UDP and sockets. It allows the caller to do
non-blocking send and receive of free form datagrams, with an optional timeout.
(back to map)
nvpair
- nvpair is an abstraction around data structures that are sets of name-value pairs.
It can be thought of as a subset of XML or ClassAds, without requiring the immense
libraries and portability problems posed by external software. nvpairs can be output
in a variety of formats compatible with other software. Used extensively by catalog_query
and catalog_server.
(back to map)
debug
- The debugging module is used by nearly every module in the system.
A single function, debug, allows various modules to record printf-like strings.
Each main program choose what debugging flags it wishes to enable, allowing
for fine grained information about each module to be enabled and disabled at will.
Messages may be sent to the console, to a rotating file, or by UDP to a debug server
on the network.
(back to map)
catalog_query
- Implements queries on the catalog server, returning the results as a series
of nvpair objects that can be examined for further detail. Used by the chirp_global
module to build a list of all servers. Makes use of the http_query and nvpair
modules to implement the query.
(back to map)
http_query
- Implements simple HTTP/1.0 requests on HTTP servers.
Only a very few features are supported. Object redirections are handled silently
by generating a new query internally. Connections are not cached. Uses the link
module for network access. Used by pfs_service_http and catalog_query.
(back to map)
catalog_server
- Implements the global catalog of chirp_servers. Each server sends periodic updates
to the catalog via UDP datagrams. Queries to the catalog are made via HTTP queries.
Data may be returned in a variety of formats. Records are stored in a hash_cache
and discarded if a server is not heard from in 30 minutes.
(back to map)
hash_cache
- Implements a cache of arbitrary objects hashed by a string name and given an expiration time.
Objects that stay in past the expiration time are automatically deleted and ignored
during a lookup pass. Uses hash_cache in order to implement the hash_table.
(back to map)
hash_table
- Implements a hash table of arbitrary objects indexed by string name.
Objects may be anything that can be cast to a void pointer.
The caller is responsible for allocating and de-allocating the objects.
(back to map)
auth
- Implements an authentication negotiation mechanism. Both clients and servers must
call auth_register at startup to indicate which authentication mechanism they wish to use,
as well as the preferred order.
(One may call auth_register_all to register all known types in a fixed order.)
Upon establishing a connection, clients call auth_assert to assert their identity,
while servers call auth_accept. An acceptable mechanism is negotiated, and then the
underlying module actually attempts to authenticate.
(back to map)
auth_hostname
- The simplest authentication module simply identifies the calling client by performing
a reverse DNS lookup on its IP address. If successful, the client is then known by
a name such as hostname:fred.cse.nd.edu
(back to map)
auth_unix
- This module can identify local users. The client is challenged to touch a file in a local file system.
If the client is able to do so, the server infers the client's identity from the owner of the created file.
The server then knows the client to be that Unix user. Only makes sense when authenticating to a server
on the same system. If authentication succeeds, the client is known by a name such as unix:fred
(back to map)
auth_kerberos
- Implements authentication using the Kerberos system. Note that the server must be running as root
in order to access the local Kerberos credentials. If authentication succeeds, the client is known
by a name such as kerberos:fred@nd.edu
(back to map)
auth_globus
- Implements authentication using the Globus Security Infrastructure. The client must have a Globus
certificate, and have generated a proxy with grid-proxy-init. The server must also have Globus credentials
as well. If authentication succeeds, the client is known by a name such as /O=NotreDame/CN=Fred
(back to map)