PRUNE: The Preserving Run Environment
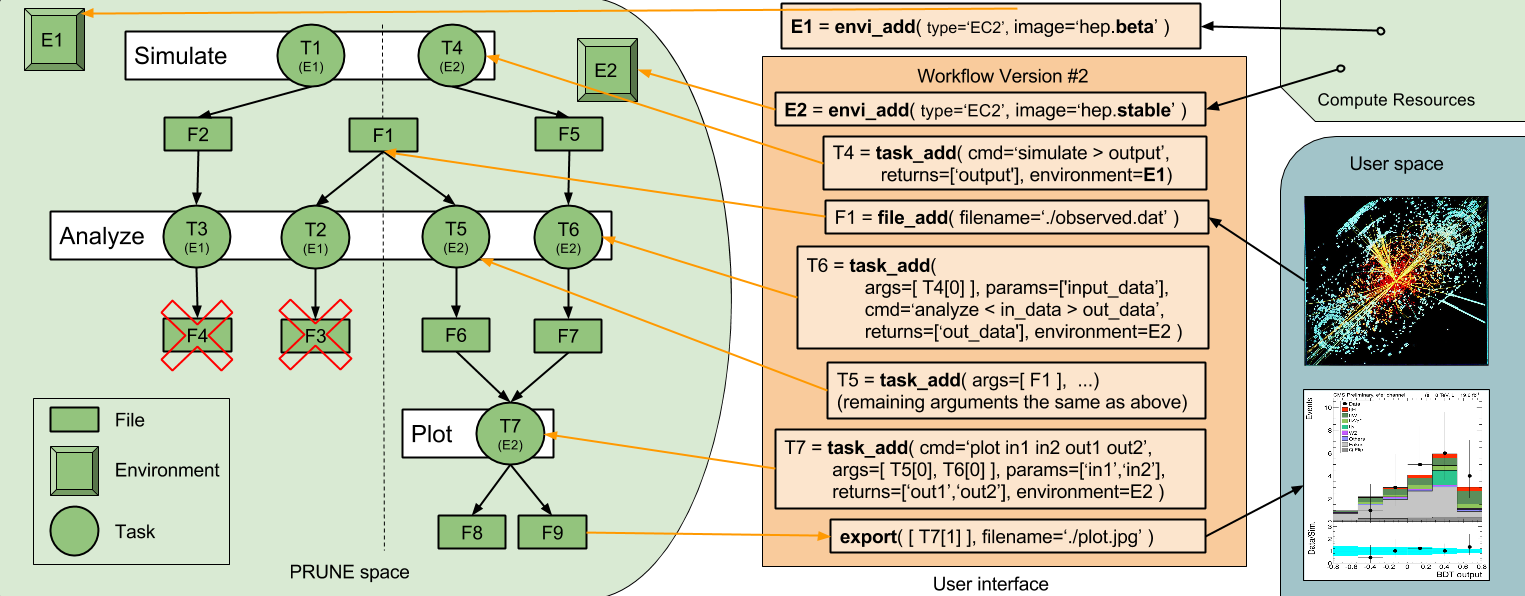
Prune is designed to preserve the evolution of scientific workflows so that they can be easily verified or expanded upon by other researchers. Execution of the workflow is also performed through Prune to ensure that it has all information necessary to restore the workflow as it was at any point in time, such as when results were used in a publication.
Some other preservation solutions force the user to use specific low-level operations to make up the workflow or automatically preserve those low-level operations. Prune gives the user full control over the granularity by which operations are defined in the workflow. This makes it much easier for a human to understand the workflow after the fact.
Despite this flexibility Prune enables preservation by providing a framework for the researcher to explicitly state (in advance) all data, software, and hardware dependencies for any given operation in the workflow. As a workflow executes, intermediate data can be deleted with the knowledge that it could be re-generated later if needed, which allows Prune to execute workflows with reduced storage requirements. Even final published results can be deleted as the workflow evolves because the data required to re-generate those published results is retained. All this can be done in the background with no worry about accidentally deleting some data that might be needed in the future. Prune assumes that the data about the workflow and the software used to execute it consume much less space than the actual data generated at each stage of the workflow. If this is the case Prune could store a workflow as it evolves over many years.
Both content based and derivation based identifiers are stored in the Prune repository. They are used to detect and prevent duplicate execution and storage. This can be done in an ad hoc distributed manner across repositories, and in some cases they can even detect logical equivalence when files are bitwise disparate due to timestamps or intentional randomness based on statistical models. Additional naming designed to be readable to the user can be done in a Python script which describes the Prune operations that make up a workflow.
More Info
Publications
(Showing papers with tag prune. See all papers instead.)

|
Peter Ivie and Douglas Thain, |

|
Douglas Thain, Peter Ivie, and Haiyan Meng, |