
Data Intensive Grid Computing on Active Storage Clusters
PI: Douglas Thain. This work is supported by the National Science Foundation under grant CNS-06-43229.Distributed computing has traditionally focused on managing the computation needs of large scale science. However, as CPUs outpace storage and networking technologies, managing the data required by scientific applications is becoming more and more critical. Traditional abstractions such as filesystems have not proven to be sufficient for these needs. Instead, new mechanisms and algorithms are needed to ensure that computation and data are partitioned and performed in an efficient manner.
Foundation: The Tactical Storage System
 In order to execute data intensive applications, we must have
a software foundation that allows us to harness and access storage
and computing in a coordinated manner.
This software is called the
tactical storage system (TSS).
Deployed on a large network of machines [catalog - visual] at the University of Notre Dame, the TSS allows ordinary users to construct and employ
complex storage structures such as filesystems and databases, share
them with external users via fine-grained security policies and a decentralized group system, manage local space
through an allocation mechanism., and securely execute code close to data using a technique called
identity boxing.
In order to execute data intensive applications, we must have
a software foundation that allows us to harness and access storage
and computing in a coordinated manner.
This software is called the
tactical storage system (TSS).
Deployed on a large network of machines [catalog - visual] at the University of Notre Dame, the TSS allows ordinary users to construct and employ
complex storage structures such as filesystems and databases, share
them with external users via fine-grained security policies and a decentralized group system, manage local space
through an allocation mechanism., and securely execute code close to data using a technique called
identity boxing.
Techniques for Computing on Distributed Storage
Given the ability to store and access data on a large number of disks in a cluster, we can begin to view scientific computation and data analysis in a new way.This simplest is just to view a cluster as a large, endlessly expandable storage device. For example, the GRAND astrophysics experiment at Notre Dame employs tactical storage to build a high-capacity filesystem on a cluster of commodity machines. By employing parallel disks, we have improved the throughput of data processing by several orders of magnitude. As more capacity or thoughput is needed, the software can be instructed to harness additional cluster nodes, regardless of their hardware or location.
A more complex example is to use multiple storage devices and protocols distributed across the wide area. Many scientific codes employ a common set of large datasets that are impractical for every user to replicate. However, given a replication location service, multiple codes can access the same copy of data. Our software permits users to harness distributed copies, regardless of their location or storage prototocol, without changing the underlying application. This approach has been used by the IBCP bioinformatics group at the University of Lyon, the CDF high energy physics experiment at Fermi National Lab, and the BaBar experiment at CERN.
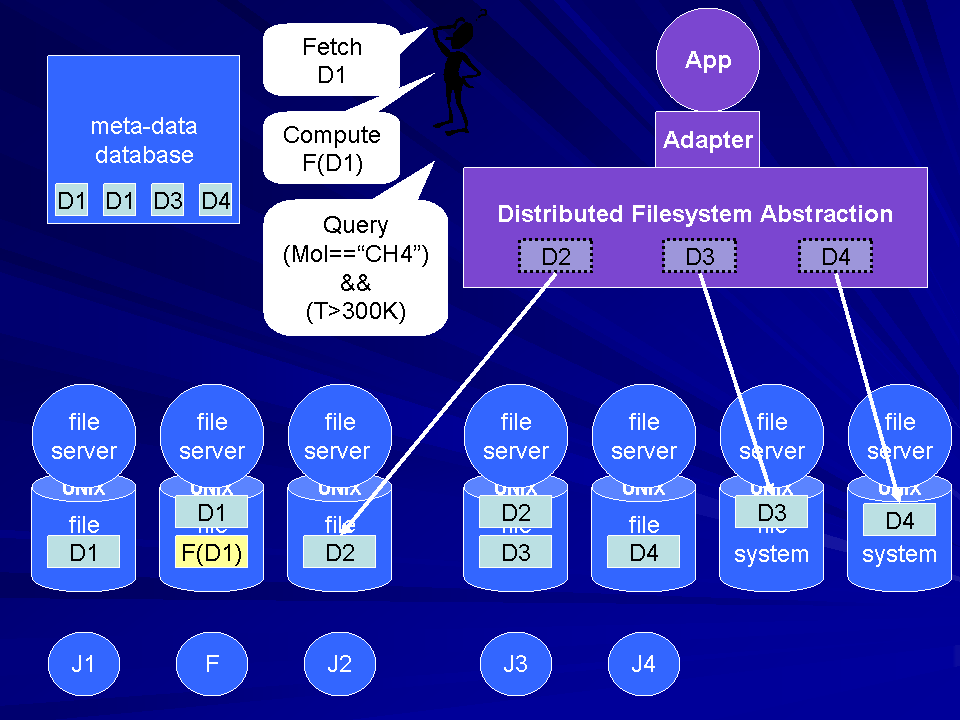 An unconventional view is to consider a cluster as a database facility for both generating,
tracking, and post-processing simulations.
The GEMS
distributed database for molecular dynamics simulation uses
a simulation database as an index into distributed storage.
This allows the end user to submit simulation queries which are then
either computed or returned as needed. Local storage and computation
are employed to minimize network computation. A functional programming
style is used to name and access computation and data easily.
An unconventional view is to consider a cluster as a database facility for both generating,
tracking, and post-processing simulations.
The GEMS
distributed database for molecular dynamics simulation uses
a simulation database as an index into distributed storage.
This allows the end user to submit simulation queries which are then
either computed or returned as needed. Local storage and computation
are employed to minimize network computation. A functional programming
style is used to name and access computation and data easily.
Publications
(Showing papers with tag filesystems. See all papers instead.)
|
Chao Zheng, Lukas Rupprecht, Vasily Tarasov, Douglas Thain, Mohamed Mohamed, Dimitrios Skourtis, Amit S. Warke and Dean Hildrebarnd, |

|
Tim Shaffer and Douglas Thain, |

|
Jakob Blomer, Predrag Buncic, Rene Meusel, Gerardo Ganis, Igor Sfiligoi and Douglas Thain, |

|
Patrick Donnelly and Douglas Thain, |

|
Hoang Bui, |

|
Douglas Thain, Michael Albrecht, Hoang Bui, Peter Bui, Rory Carmichael, Scott Emrich, and Patrick Flynn, |

|
Patrick Donnelly, Peter Bui, Douglas Thain, |

|
Hoang Bui, Peter Bui, Patrick Flynn and Douglas Thain, |

|
Gabrielle Compostella, Simone Pagan Griso, Donatella Lucchesi, Igor Sfiligoi, and Douglas Thain, |

|
Hoang Bui, Michael Kelly, Christopher Lyon, Mark Pasquier, Deborah Thomas, Patrick Flynn, and Douglas Thain, |

|
Douglas Thain, Christopher Moretti, and Jeffrey Hemmes, |

|
Douglas Thain and Christopher Moretti, |

|
Christopher Moretti, |

|
Christophe Blanchet, Remi Mollon, Douglas Thain, and Gilbert Deleage, |

|
Douglas Thain, |

|
Jeffrey Hemmes and Douglas Thain, |

|
Sander Klous, Jamie Frey, Se-Chang Son, Douglas Thain, Alain Roy, Miron Livny, and Jo van den Brand, |

|
Stefano Belforte, Matthew Normal, Subir Sarkar, Ifor Sfiligoi, Douglas Thain, Frank Wuerthwein, |

|
Douglas Thain, Christopher Moretti, and Igor Sfiligoi, |

|
Douglas Thain, Christopher Moretti, Paul Madrid, Phil Snowberger, and Jeff Hemmes, |

|
Douglas Thain, Sander Klous, Justin Wozniak, Paul Brenner, Aaron Striegel, and Jesus Izaguirre, |

|
Douglas Thain and Miron Livny, |

|
John Bent, Douglas Thain, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau, and Miron Livny, |

|
Douglas Thain and Miron Livny, |

|
Douglas Thain, Jim Basney, Se-Chang Son, and Miron Livny, |